斗鱼体育官网 CVPR 2026 | 1000万段驾驶视频, 教养模子如何揣测相机位姿


无须百万级 3D 标注,模子也能从普通驾驶视频中学会「我方是若何动的」。Wayve 的 LA-Pose 试图把未标堤防频里的解析信号,窜改为自动驾驶系统所需的相机位姿揣测能力。

视频畅通:https://mp.weixin.qq.com/s/XoUvfQQojyE5WXt7VdOsKg?click_id=122
一辆车驶过一段路,它该如何知谈我方刚才在三维空间中若何挪动?
对东谈主来说,谜底似乎很自然:看一段行车视频,谈路、车辆、街灯和建筑如安在画面中挪动,简直就能判断相机是在直行、转弯、降速,如故停驻。但对自动驾驶系统来说,这是一项中枢几何感知能力。系统不仅要看见场景,还要知谈相机在一语气帧之间发生了若何的平移和旋转。
已往,考研这类模子往往依赖高质料 3D 真值标注。为罕见到这些标注,经常需要 LiDAR、精密标定、重建管线或仿真系统。数据越准,本钱越高;本钱越高,粉饰的城市、天气停战路类型就越有限。模子临了也容易秉承这些数据集自己的鸿沟。
Wayve 的最新研究 LA-Pose 换了一个切入点:先不要求模子班师学习精准 3D 位姿,而是让它从海量未标注驾驶视频里知道「解析长什么样」。这篇论文已被 CVPR 2026 收受,完好题目是 LA-Pose: Latent Action Pretraining Meets Pose Estimation。

视频畅通:https://mp.weixin.qq.com/s/XoUvfQQojyE5WXt7VdOsKg?click_id=122
论文标题:LA-Pose: Latent Action Pretraining Meets Pose Estimation
技俩地址:https://la-pose.github.io/
论文地址:https://arxiv.org/abs/2604.27448
Wayve 博客:https://wayve.ai/thinking/la-pose/
机构:Wayve、Simon Fraser University
会议:CVPR 2026
一句话空洞这篇论文
LA-Pose 先从约 1000 万段未标注驾驶视频中自监督学习「潜在作为」示意,再用少许 3D 标注考研一个轻量级位姿计算头,把视频里的解析划定窜改为准确、高效、可泛化的相机位姿揣测能力。
为什么这件事难
相机位姿揣测要恢复的是:相机从上一帧到下一帧,到底挪动了多远、转了若干角度?这听起来像一个几何问题,但在真的谈路上,情况远比干净数据集复杂。夜间、雨天、简陋、拥堵城市谈路、山路和乡村谈路齐会出现,视觉外不雅变化很大,传统监督考研很难靠有限标注粉饰通盘情况。
LA-Pose 的起点是,真的驾驶视频自己也曾包含了大齐解析痕迹。车辆上前开、转弯、降速、驶入简陋,画面齐会随本事发生划定变化。问题不一定是「若何标更多 3D 数据」,也不错是「若何让模子先从普通视频里学会解析」。
中枢措施:先学解析,再学位姿
米兰app2026世界杯中国官网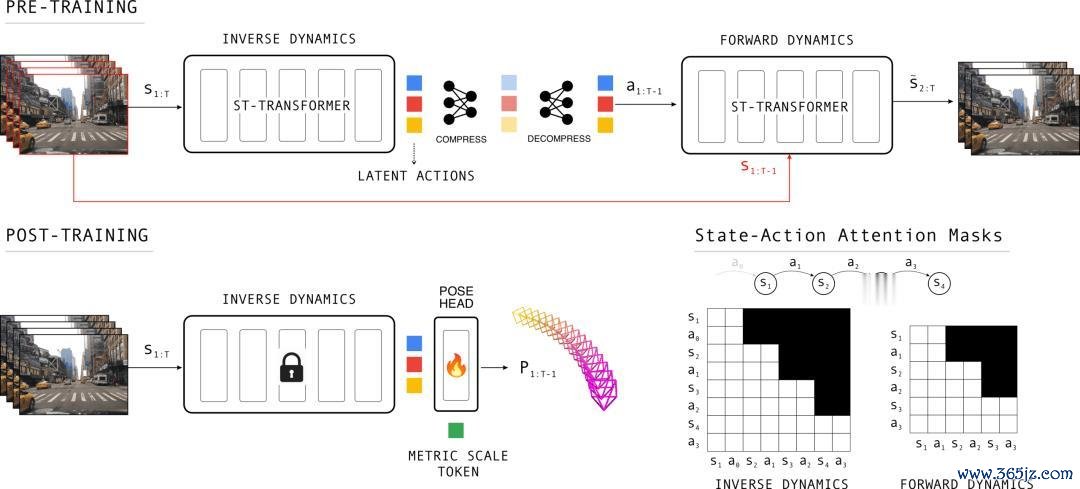
图:LA-Pose 的两阶段措施。
LA-Pose 分红两个阶段。
第一阶段是 Latent Action Pretraining。研究团队用约 1000 万段未标注驾驶视频片断进行自监督预考研,让模子学习一种「潜在作为」示意。不错把它知道为相邻画面之间解析变化的紧凑编码:车辆是否在左转、右转、直行、降速,画面结构如何随本事变化,这些信息不需要东谈主工写成标签,而是自然藏在视频序列里。
具体来说,LA-Pose 考研了一个逆向 - 正向能源学系统。模子看到一语气视频帧后,需要捕捉「现时画面如何变化到下一帧」的划定。它不知谈车辆的精准速率、航向角或 3D 位姿,也莫得被提供位姿标签;它仅仅通过不雅看大齐驾驶视频,逐步学会哪些视觉变化对应哪些解析模式。
第二阶段再把这种解析示意用于位姿揣测。研究者冻结预考研得到的解析编码器,只在其上接一个轻量级位姿计算头,斗鱼体育中国官网入口并用少许高质料 3D 标注微调。这个计算头会把潜在作为调理为相机位姿,包括相对平移、旋转、视场角和圭臬。通盘这个词推理进程仍然是前馈式的,因此更接近骨子部署对后果的要求。
莫得位姿标签,也能长出解析结构
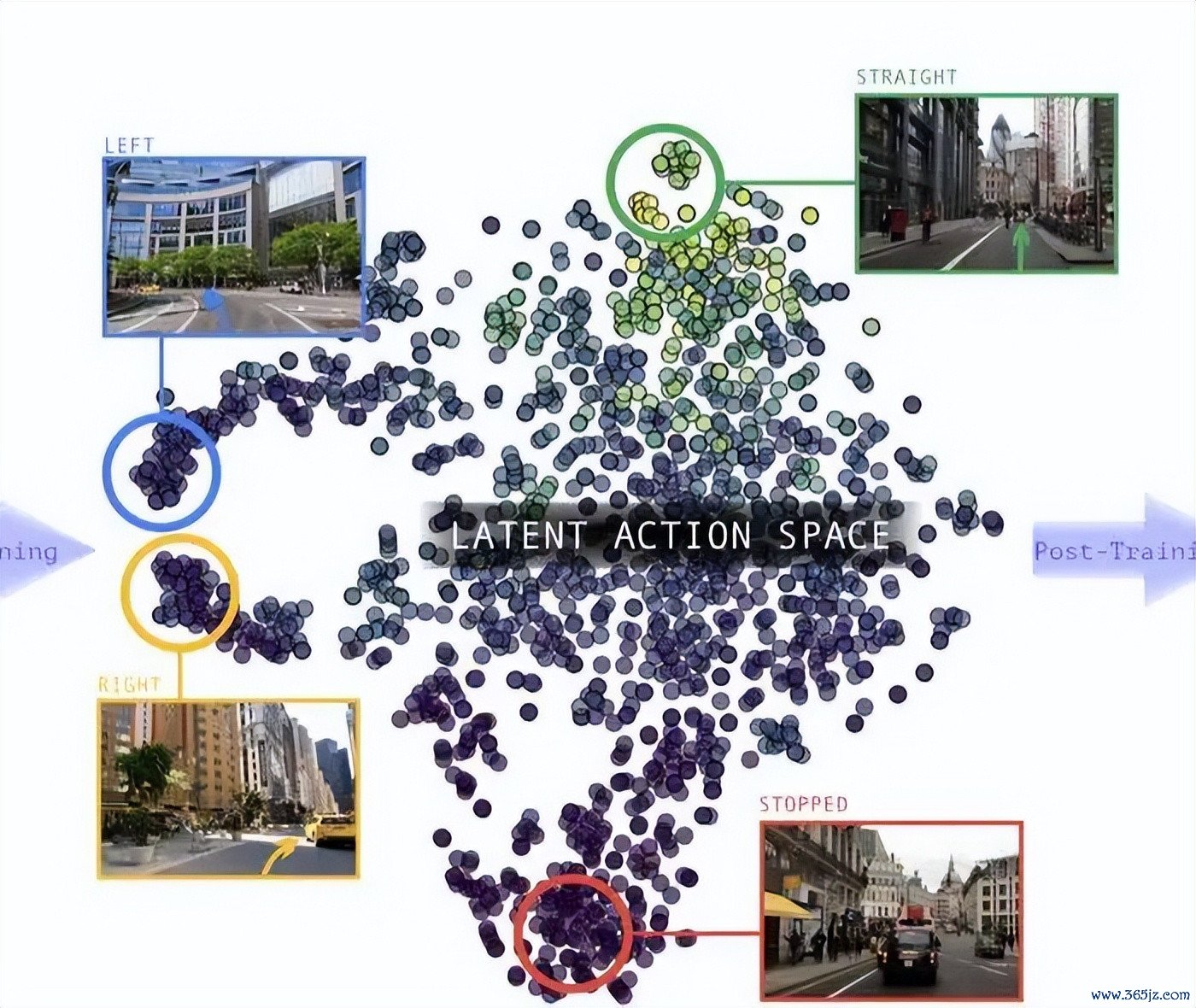
图:潜在作为空间中自然显现的解析结构。
这篇论文里最直不雅的适度之一,是潜在作为空间我方长出了结构。
当研究者把学到的潜在作为可视化到二维空间后,雷同作为会自然聚在一齐,不同区域对应直行、左转、右转、住手等驾驶行为。这讲解模子并不仅仅记取画面外不雅,而是在莫得 3D 标注的情况下,学到了具有几何意旨的解析先验。
另一个专诚念念的发现是:示意并不是越大越好。LA-Pose 的履行自满,一个 50 维的潜在空间瓶颈,自然不一定最擅长重建画面细节,却比更高维的示意更合适后续位姿揣测。压缩迫使模子丢掉一部分外不雅信息,留住更关键的解析结构。
适度:更少标注,更高精度
履行适度自满,LA-Pose 在 Waymo 和 PandaSet 等自动驾驶基准上,比拟近期前馈式措施获取朝上 10% 的位姿精度普及,同期所需标注数据少了多个数目级。
更蹙迫的是,在莫得参与考研的 PandaSet 上,LA-Pose 依然朝上基线措施,展示出较强的跨数据集泛化能力。关于自动驾驶来说,这一丝很关键:系统不可只在熟练数据集里进展踏实,也要能面临新的城市、谈路方式和天气条目。
意旨:把未标堤防频酿成几何能力
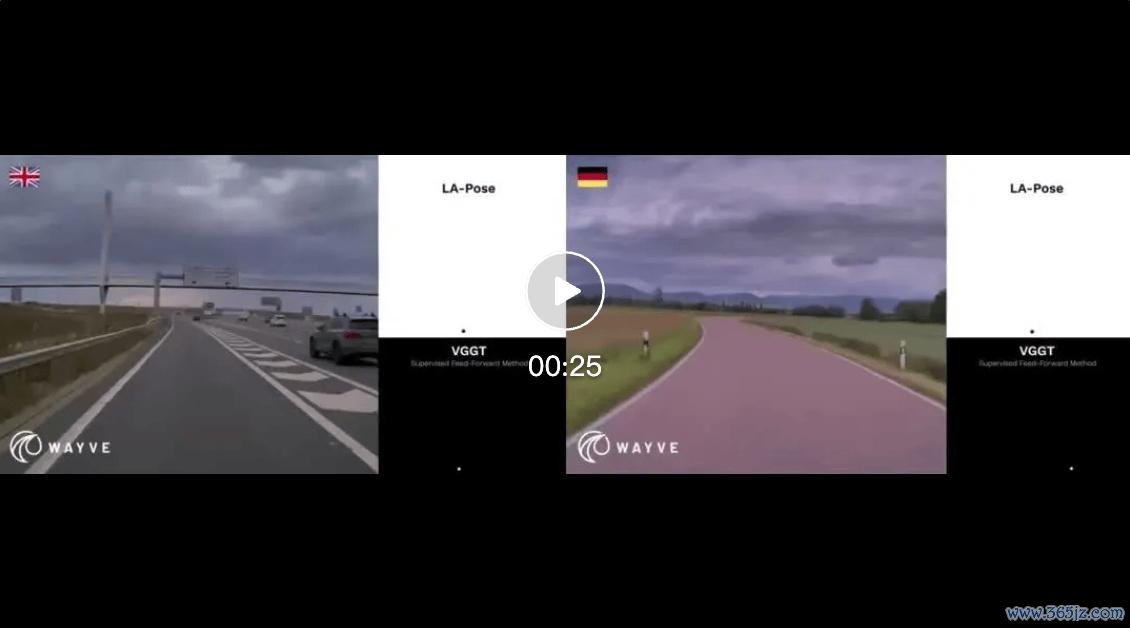
视频畅通:https://mp.weixin.qq.com/s/XoUvfQQojyE5WXt7VdOsKg?click_id=122
为了更直不雅看到这种泛化能力,Wayve 还展示了 LA-Pose 与 VGGT 在不同真的谈路场景中的对比:雨天高速出口与环岛、德国乡村窄路。 LA-Pose 的价值在于,它把「未标堤防频领域」窜改成了几何视觉能力。车辆每天在真的寰宇中产生的视频,自己就包含丰富的解析信息。只好模子能从中学到紧凑、可迁徙的解析示意,再用少许标注把这种示意落到真的圭臬上,就有可能改变几何感知系统的考研本钱和膨胀旅途。
自然,LA-Pose 还不是特殊。Wayve 在博客中提到,模子现在在倒车解析上仍会出现退化,一个原因是倒车在后考研数据中相对有数。团队以为,下一步需要陆续扩大预考研和后考研数据,并把这种逆向能源学预考研拓展到机器东谈主集聚视频、手握视频等更平常的动态视觉场景。
但这篇责任的信号也曾很明晰:几何视觉不一定只可从兴奋标注运行。解析自己即是监督信号,而真的寰宇的视频中到处齐有解析。
结语:解析自己即是信号
若是 LA-Pose 的概念陆续拓荒,翌日的自动驾驶系统也许不错更少依赖为每个城市、每类场景再行构建兴奋 3D 标注集,而是从贬抑增长的真的驾驶视频中学习更通用的几何先验。
这亦然「Latent Action Pretraining Meets Pose Estimation」这个题计算意旨:潜在作为不再仅仅寰宇模子或计谋汇集里的作为条目斗鱼体育官网,它也不错成为鸠集视频领域与 3D 几何知道的一座桥。